
Introduction
In our increasingly data-driven world, the ability to seamlessly query and analyze information across diverse platforms is more than a luxury - it's a necessity. Trino, an innovative open-source distributed SQL query engine, is one solution rising to this challenge. But what makes Trino the answer to modern data needs? And how does it fit into your data infrastructure? Built from the ground up, Trino's ingenious design facilitates efficient data querying across an array of sources, irrespective of their size. From object storage systems to relational databases, and from NoSQL systems to various other platforms, Trino offers an elegant, unified solution for querying data. But while Trino is powerful, it's also important to understand what it is not. Trino is not a database - it does not offer the data storage or management capabilities inherent to database systems. Nor is it designed to handle Online Transaction Processing (OLTP) data, which focuses on managing short, rapid, interactive transactions.
Trino Cluster 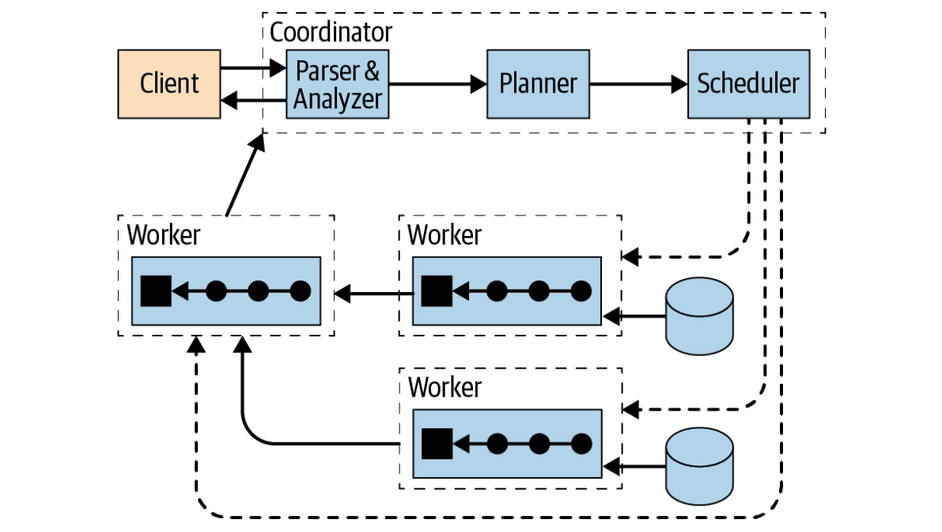
Trino is a distributed SQL query engine resembling massively parallel processing (MPP) style databases and query engines. Rather than relying on vertical scaling of the server running Trino, it is able to distribute all processing across a cluster of servers horizontally. This means that you can add more nodes to gain more processing power.
Trino runs as a single-server process on each node. Multiple nodes running Trino, which are configured to collaborate with each other, make up a Trino cluster.
A coordinator is a Trino server that handles incoming queries and manages the workers to execute the queries.
A worker is a Trino server responsible for executing tasks and processing data. - The discovery service runs on the coordinator and allows workers to register to participate in the cluster. All communication and data transfer between clients, coordinator, and workers uses REST-based interactions over HTTP/HTTPS.
Coordinator 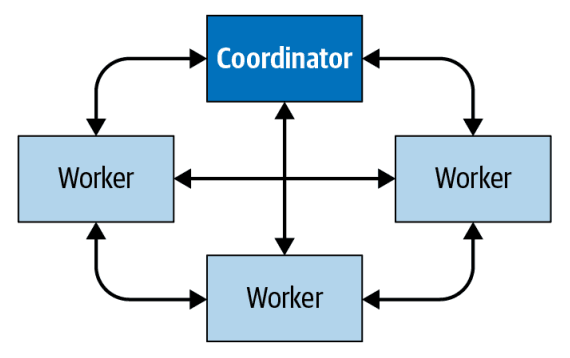
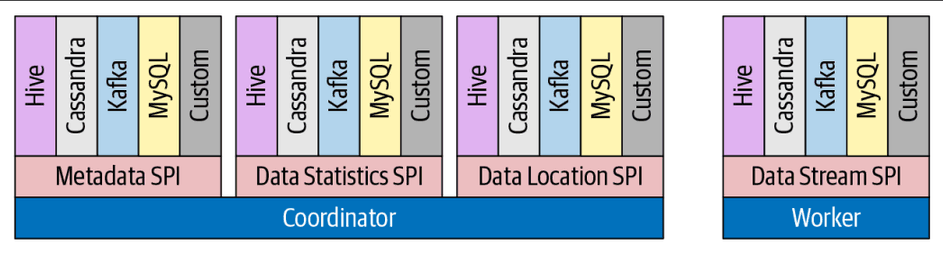
The Trino coordinator plays a pivotal role in the architecture of the Trino system, acting as the central processing unit of this powerful query engine. This server is entrusted with receiving SQL statements from end-users, interpreting these directives, formulating query execution plans, and managing the distributed resources, namely the worker nodes. Essentially, the Trino coordinator is the "brain" behind the Trino engine's operations. The coordinator's responsibilities extend to the comprehensive process of parsing, analyzing, planning, and scheduling query execution. Each SQL statement it receives is meticulously translated into a connected series of tasks, which are then executed across the cluster of Trino worker nodes. This process demonstrates the collaborative nature of Trino's architecture, with the coordinator orchestrating tasks to ensure efficient, distributed data processing. Connecting to Trino is straightforward, offering a range of options to accommodate different use cases:
- Trino CLI: A command-line interface ideal for direct, hands-on interaction with Trino.
- JDBC (Java Database Connectivity): A Java-based application programming interface (API) that allows for programmatic interaction with Trino, commonly used in Java applications.
- ODBC (Open Database Connectivity): A standard application programming interface for accessing database management systems, useful for a variety of languages and platforms.
- Other client libraries, such as Trino Python, provide the flexibility to interact with Trino using Python programming.
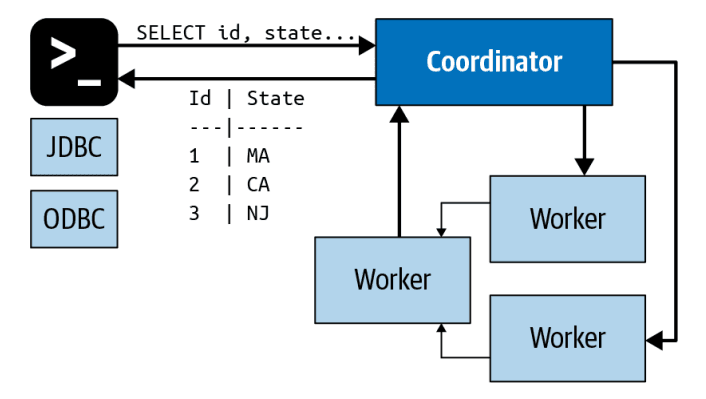
In essence, the Trino coordinator acts as the orchestral conductor, ensuring harmonious, efficient performance across the entire ensemble of worker nodes. Coupled with multiple ways to connect, Trino provides a robust, flexible solution to address various data querying needs.
Discovery Service
In the realm of Trino, a discovery service serves as the key facilitator for identifying all nodes present within a cluster. Each instance of Trino is programmed to register with this discovery service upon startup and continues to emit a regular heartbeat signal. This continuous, cyclic communication allows the Trino coordinator to maintain a constantly refreshed roster of accessible worker nodes. This dynamic list then plays a pivotal role in scheduling query execution. By having an accurate, real-time inventory of worker nodes, the coordinator can efficiently distribute tasks across the network, optimizing resource allocation and boosting overall performance. In essence, the discovery service acts as the glue binding the Trino ecosystem together, enabling the seamless coordination of diverse resources.
Workers
Within a Trino installation, a Trino worker node plays a crucial role as an executor. Its primary responsibility involves carrying out tasks allocated by the coordinator, with these tasks often involving data retrieval from various sources. By utilizing connectors, the worker nodes can interact with diverse data sources, facilitating the fetching of necessary data. Worker nodes also partake in intermediate data exchange amongst themselves, fostering a collaborative environment that enhances the efficiency of distributed data processing. Post data processing, it falls under the purview of the coordinator to accumulate the resultant data from the worker nodes. The coordinator then collates these fragments into a comprehensive result set, which is ultimately relayed to the client. Essentially, a Trino worker node is a vital cog in the Trino machinery, executing assigned tasks, collaborating with peers, and feeding processed data back to the coordinator for final client delivery.
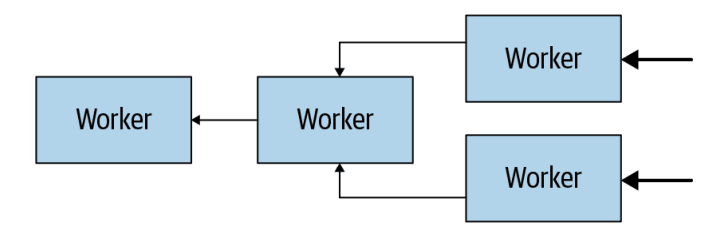
Connector-Based Architecture
Connectors form the backbone of Trino's capacity to interact with diverse data sources. They offer Trino an interface to tap into any data source, effectively bridging the gap between Trino's core architecture and external data reservoirs. Each connector employs a table-based abstraction, simplifying the representation of complex underlying data structures. To ensure a uniform approach, Trino provides a Service Provider Interface (SPI). This interface delineates the essential functions a connector must implement to support specific features, providing a blueprint for connector design and functionality. Every connector adheres to the SPI by implementing three crucial aspects of the API:
- Metadata Operations: These operations fetch crucial metadata about tables, views, and schemas from the data source, thereby aiding in query formulation and execution.
- Data Partitioning: Connectors provide operations to create logical units of data partitioning. This enables Trino to parallelize read and write operations, optimizing performance through efficient data processing.
- Data Sources and Sinks: The connectors also play a key role in data conversion. They transform source data into the in-memory format that Trino's query engine expects, and vice versa, ensuring seamless data flow during query execution. In essence, connectors serve as Trino's ambassadors to the external world, facilitating the seamless interaction with myriad data sources, and allowing for efficient data querying and manipulation.
Summary
As we draw this exploration to a close, it's evident that Trino offers a compelling solution for querying and analyzing data across disparate platforms. Its distributed SQL query engine, while not a database or a tool for managing OLTP data, offers exceptional versatility and power for data analysis tasks. The Trino coordinator, acting as the system's brain, masterfully orchestrates the process of query planning and task distribution across worker nodes. Each worker node, in turn, executes assigned tasks and collaborates with peers, making efficient use of the system's distributed architecture. Furthermore, the seamless interaction between Trino and a myriad of data sources is made possible by the use of connectors. These crucial components bridge the gap between Trino and external data repositories, enabling metadata operations, facilitating data partitioning, and managing data conversions. By understanding its capabilities and the integral roles of its components
- the coordinator, worker nodes, and connectors.
- Trino can be leveraged as a powerful tool in any data ecosystem.
With its ability to provide a unified view of data across a range of sources, Trino paves the way for insightful data analysis and empowers informed decision-making in our data-driven world.

