
Searching in a large table housing billions of rows can be challenging, particularly when querying for fuzzy matches, typos, and partial words. In tackling this complexity, PostgreSQL emerges as a powerful relational database, offering impressive text search features, such as trigram indexes. Although Elasticsearch is often regarded as a dedicated solution for text searches, PostgreSQL’s capabilities enable fast and flexible search without requiring additional infrastructure, data synchronization, or complex authorization logic.
In this blog post, we will explore the GIN index, its structure, and its usage with trigram operations.
What is the GIN Index?
GIN stands for Generalized Inverted Index. "Inverted" refers to the way that the index structure is set up, building a table-encompassing tree of all column values, where a single row can be represented in many places within the tree. By comparison, a B-tree index generally has one location where an index entry points to a specific row.
An important aspect to note is that the mapping of a column for a given data type in a GIN index is dependent on the GIN index operator class. This means that, unlike B-trees which have a uniform data representation, a GIN index can have varied index contents based on the data type and operator class in use.
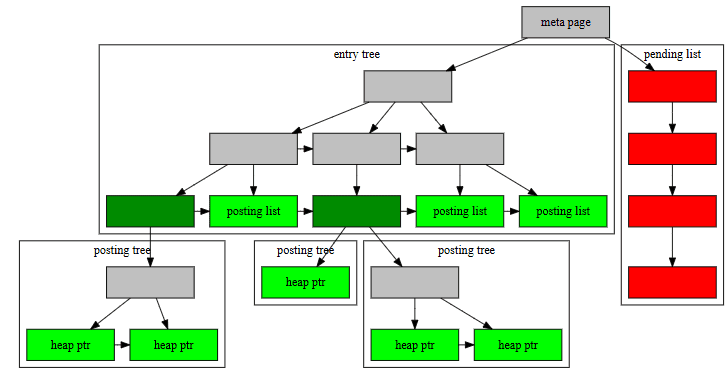
GIN Index Architecture
Internally, a GIN index contains a B-tree index constructed over keys, where each key is an element of one or more indexed items and where each tuple in a leaf page contains either a pointer to a B-tree of heap pointers (“posting tree”), or a simple list of heap pointers ( “posting list”) when the list is small enough to fit into a single index tuple along with the key value.
Indexing LIKE searches with Trigrams and gin_trgm_ops
To perform similarity searches on text columns, such as finding rows containing words similar to a given query, an operator class can be utilized. The gin_trgm_ops option in PostgreSQL specifies how an operator (e.g., LIKE) can use the index. These operator classes support LIKE, ILIKE (case-insensitive matches), ~ (case-sensitive regular expressions), and ~* (case-insensitive regular expressions).
pg_trgm: Support for Similarity Using Trigram Matching
The LIKE operation, which supports arbitrary wildcard expressions, is fundamentally challenging to index. However, the pg_trgm extension can assist with this. pg_trgm is a PostgreSQL extension that provides simple fuzzy string matching. It has lower operational and conceptual overhead than PostgreSQL full-text search or a separate search engine. This extension offers functions and operators to determine the similarity of alphanumeric text based on trigram matching, as well as index operator classes that enable fast searching for similar strings.
What is a Trigram?
A trigram is a sequence of three consecutive characters within a string. For instance, the word “Hello” yields the trigrams: “Hel”, “ell”, and “llo”. The pg_trgm extension in PostgreSQL is designed to dissect strings into individual words, subsequently computing trigrams for each. Additionally, it standardizes words by converting them to lowercase, prefixing two spaces and suffixing one. Notably, pg_trgm disregards non-alphanumeric characters during trigram extraction.
We can use the following query to see what trigrams PostgreSQL can produce:
CREATE EXTENSION pg_trgm;
select show_trgm('Hello');
show_trgm
|-------------------------|
{ h, he,ell,hel,llo,lo }
Trigram Indexes
The pg_trgm module in PostgreSQL offers GiST and GIN index operator classes, enabling the creation of indexes on text columns to facilitate rapid similarity searches. These indexes support trigram-based searches for queries using LIKE, ILIKE, ~, ~*, and =.
Given that GIN beats GiST in accuracy and search speed, and considering that a sample of data undergoes infrequent updates yet requires swift search capabilities, GIN indexes emerge as our preferred choice for this blog.
Enhancing Search Performance with GIN Index
To illustrate the effectiveness of utilizing a GIN index for wildcard searches in PostgreSQL, we have created a random table featuring a data field containing random strings. We will evaluate the performance of a search query both with and without the use of a GIN index.
Generating Random Data
Create a table called random_table with one random_string field
create table random_table( random_string varchar);
Next, populate the table with one hundred million random string records:
INSERT INTO random_table (random_string)
SELECT md5 (id::text) AS random_string
FROM generate_series (1, 100000000) AS id;
INSERT 0 100000000Example records:
random_string
----------------------------------
fddeaff5b50213118cce4c9381920ba2
d05a7a0e23be9376d427f5df0d0293aa
03c6687cea005aa90448d481c5b5c4a6Performance without GIN Index
In the query below, PostgreSQL performs a Parallel Sequential Scan on random_table to filter rows based on the presence of the substring '9376d' within the random_string column. The execution time for scanning the entire table without an index is 8153.892 milliseconds:
explain analyze select * from random_table where random_string like '%9376d%';
Gather (cost=1000.00..1356167.33 rows=10000 width=33) (actual time=34.737..8153.194 rows=2612 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on random_table (cost=0.00..1354167.33 rows=4167 width=33) (actual time=83.327..8125.675 rows=871 loops=3)
Filter: ((random_string)::text ~~ '%9376d%'::text)
Rows Removed by Filter: 33332463
Planning Time: 0.147 ms
JIT:
Functions: 6
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 0.832 ms, Inlining 184.602 ms, Optimization 36.974 ms, Emission 20.568 ms, Total 242.976 ms
Execution Time: 8153.892 msPerformance with GIN Index:
First, create the trigram extension:
CREATE EXTENSION IF NOT EXISTS pg_trgm;Next, create an index on the random_string field using the trigram extension:
CREATE INDEX trgm_idx ON random_table USING gin (random_string gin_trgm_ops);Running the same query after creating a gin index on random_table results in a performance enhancement.
explain analyze select * from random_table where random_string like '%9376d%';
Bitmap Heap Scan on random_table (cost=1988.83..38620.53 rows=10000 width=33) (actual time=86.860..103.032 rows=2612 loops=1)
Recheck Cond: ((random_string)::text ~~ '%9376d%'::text)
Rows Removed by Index Recheck: 498
Heap Blocks: exact=3101
-> Bitmap Index Scan on trgm_idx (cost=0.00..1986.33 rows=10000 width=0) (actual time=86.437..86.438 rows=3110 loops=1)
Index Cond: ((random_string)::text ~~ '%9376d%'::text)
Planning Time: 0.133 ms
Execution Time: 103.187 ms
(8 rows)The use of a GIN index on a text column with random strings significantly improves the performance of wildcard searches in PostgreSQL. As shown by the comparison of query execution times, the query with the index takes only 103.187 milliseconds, which is 98.7% faster than the query without the index that takes over 8 seconds. This approach demonstrates the effectiveness of trigram indexes in handling wildcard searches, allowing PostgreSQL to efficiently locate and filter rows based on complex patterns.
Limitations of GIN Index
While a GIN index provides efficient performance for search queries in PostgreSQL, it is essential to acknowledge its limitations due to its structure, which often contains multiple index entries for a single row being inserted. This structure supports the use cases that GIN indexes are designed for, but it also introduces significant challenges:
- 1. Updating the Index: Updating a GIN index is expensive because it may involve updating tens or, in the worst case, hundreds of index entries for a single row.
- 2. Size: GIN indexes tend to be larger in size compared to other index types due to their internal architecture.
- 3. Null Values: GIN indexes do not support null values.
- 4. Creation Time: Creating a GIN index on large tables may take a considerable amount of time. Fortunately, PostgreSQL offers the option to create it concurrently, allowing for the continued operation of writes during the index creation process, thus preventing write locks.
Summary
This blog illustrates the utilization of a trigram index, specifically the GIN index, to improve wildcard search performance in PostgreSQL. By testing the GIN index efficiency on a random table, the results reveal remarkable performance gains. Despite some limitations, such as the expense of updating the index and its larger size, PostgreSQL’s concurrent index creation feature helps overcome these challenges, providing a robust and cost-effective solution for large-scale text searches. In conclusion, PostgreSQL’s GIN index is a reliable option for enhancing search efficiency without requiring additional infrastructure, making it an invaluable tool for applications needing fast and efficient text search capabilities.

